Kubernetes can bring significant benefits to organizations operating containerized application services for either clients or internal use. A successful implementation requires a systematic approach. As with any complex platform, you must implement the appropriate configurations and processes to avoid unnecessary risk and cost to your operations.
We divide Kubernetes best practices into four service areas: mindset, efficiency, risk, and security. We focus on relevant practices, whether you’re building a cluster from scratch or using a managed service offered by a public cloud provider.
| Mindset | Do you need it? Plan beyond “lift and shift” Highly available clusters; ephemeral instances Consider containerization overhead |
| Efficiency | Use managed clusters Plan for frequent upgrades Design for two tiers of horizontal scaling Everything-as-code, version-controlled |
| Risk | Segregate and limit using namespaces Define your risk tolerance in code Assume every component will break over the next week Don’t run databases on Kubernetes |
| Security | Disable root access on containers Enable audit logging Use RBAC for a granular control Grant most permissions at the pod level |
Mindset
The container orchestration functionality delivered by Kubernetes isn’t a replacement for any legacy technologies, so if you introduce it as a new addition to your infrastructure architecture, your mindset and processes must also renew.
1 – Do you need it?
Kubernetes is popular for good reasons, but if it’s not a match for your application architecture, you could just be adding complexity into your stack for no real business benefit.
The same reasoning applies to every technology, but misusing Kubernetes would be a costly mistake because it’s complex, lies at the core of your application environment, and can cause outages if not administered correctly.
Other alternative technologies may better suit different business needs. For example, serverless computing technologies such as AWS Lambda would better match applications that occasionally execute when triggered by external events. On the other side of the computing spectrum, applications that require high-performance storage and usage around the clock would better suit dedicated servers. Introducing Kubernetes is a commitment to operational investment and optimization and is ideally suited for applications based on microservices designed to scale horizontally, as explained in this article.
2 – Plan beyond “lift and shift”
Simply moving virtual machines (VMs) to containers on Kubernetes won’t deliver much value and can introduce operational difficulties.
One source of value in Kubernetes is the ability to run fault-tolerant, horizontally-scaling applications smoothly. If your VM-based applications aren’t already architected based on this modern design paradigm, your application isn’t ready for the main features of Kubernetes yet. While you can simply host long-running containers in Kubernetes, its documentation advises: “Pods (which a container must belong to) are designed as relatively ephemeral, disposable entities,” and it’s therefore hard to keep them up and running without working against the design of the platform. For example, there are several scenarios in which Kubernetes will assume it can safely terminate a pod and create a replacement which would be a problem for containers intended to run without interruption.
That said, there are times when you must quickly migrate a legacy application to a Kubernetes platform. In those scenarios, it would be best to share a network between legacy virtual machines (VM) and the new containers hosted on a Kubernetes cluster and migrate the VMs one by one to containers as software developers refactor the legacy application module by module.
3 – Architect applications to use disposable containers
As mentioned above, pods – the fundamental compute unit in Kubernetes – are designed to be disposable, so they suit applications that can continue to run normally when an instance disappears. This concept isn’t new – designing software to withstand individual hardware node failures became commonplace as applications moved from mainframes to a client-server architecture. Containerization and cloud computing have taken this idea to the next level.
A highly available application needs to continue serving user requests and not lose data whenever any individual Kubernetes pod terminates.
RESTful applications – a standard design for microservices communicating via APIs – meet these requirements by offloading the application’s state management to isolated database services and allowing session requests initiated from the browsers of end-users to be load-balanced between the remaining stateless container instances. When traffic is load-balanced across pods of containers in this manner, the failure of a single container cannot take down the whole application thus each container becomes disposable.
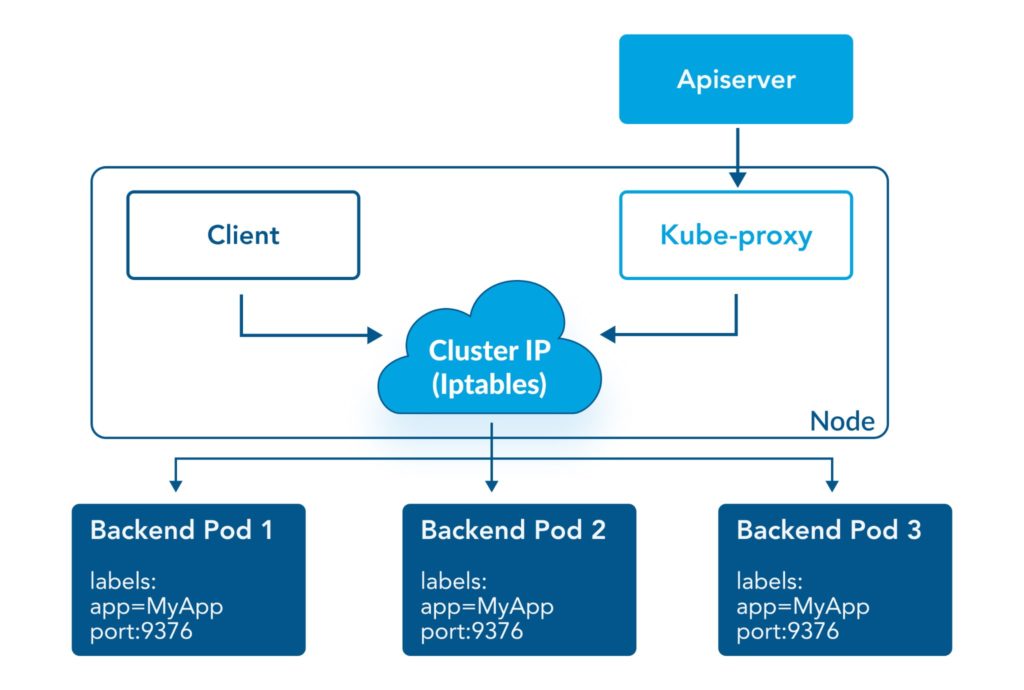
4 – Consider containerization overhead
For many cases, any performance impact is negligible or undetectable. However, if your application requires performance optimization at the operating system (OS) level, you could encounter problems running it inside a container.
Even applications that don’t integrate tightly into the OS may lose performance when migrated to containers. Sometimes, performance issues only arise because containers share the same OS kernel. On an orchestration platform like Kubernetes, where the placement of containers is automated (and random if not thoughtfully configured), these issues can be complex to diagnose and fix.
Efficiency
5 – Use managed clusters
Unless you have a large engineering department with teams already used to running open-source software as highly available services, then a managed Kubernetes service, either in the cloud or on-premise, will substantially lower its complexity by having fewer components to administer and upgrade.
etcd, in particular, has caused pain for many teams trying to run clusters. etcd is the default backend key-value pair storage for Kubernetes that saves configuration data and cluster metadata, which is critical to Kubernetes availability and performance but comes with high operational complexity.
6 – Plan for frequent upgrades
The Kubernetes development community regularly releases features that improve the operational experience and are relevant to most users. The release cycle is fast since the open-source community releases around three minor versions a year and provides security support for each for approximately one year.
Consequently, no secure Kubernetes deployment can last for more than a year. The same is true of managed services offered by major public cloud providers since they don’t offer long-term support for older versions of Kubernetes.
7 – Design for two tiers of horizontal scaling
For all but the most significant traffic spikes (where you will still want to increase capacity manually in advance), you can automatically configure Kubernetes to scale your cluster up and down, rightsizing your capacity based on actual traffic.
This scaling happens at two levels. Firstly, Kubernetes can adjust the size of the pods or increase their count to handle more requests on the hardware capacity you already have. Secondly, when you need space for more computing capacity within the cluster, Kubernetes can automatically provision additional cluster nodes.
Kubernetes allows administrators to control both pod and cluster autoscaling based on configuration parameters tied to CPU and memory usage or by leveraging custom application metrics such as the volume of user sessions.
8 – Everything-as-code, version-controlled
Kubernetes supports the concept of Infrastructure as Code (IaC). This revolutionary principle has allowed operations departments to reduce human errors and increase overall service confidence by treating infrastructure changes the same way as software changes.
This approach means that a change to a pod can take the form of a “pull request,” which is jargon for a change approval request as part of a distributed version control process. That configuration change can then be peer-reviewed, scanned for security issues, packaged, tested in a staging environment before being deployed into a production environment in the same way teams collaborate to develop software applications. Infrastructure as Code (IaC) can apply all of the typical steps involved in a software development lifecycle (SDLC) workflow to infrastructure.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Sample configuration for a Kubernetes deployment with two pods (source).
Risk
9 – Segregate and limit using namespaces
Namespaces are an effective tool for administrative isolation in a Kubernetes cluster by creating virtual separation used in access control policies. Teams can use them to avoid disrupting each other’s services accidentally.
Namespaces also support the concept of a resource quota which limits the amount of CPU and memory available to each namespace allowing administrators to control resource usage across teams in a cluster.
10 – Define your risk tolerance in code
Kubernetes functionality like disruption budgets, Quality of Service (QoS), topology spread constraints, and anti-affinity rules give you control to define your tolerance to different kinds of application failure modes. These control features present many configuration options for managing workload placement.
For example, you can prevent two pods from running on the same cluster node to protect against a single node outage which can lead to application downtime. For a more scalable approach to avoiding a single point of failure, you can configure Kubernetes deployments (a collection of stateless pods of containers) such that pods spread across multiple failure zones. You can also ensure that each cluster node gets one and only one pod to host a utility such as virus protection software.
11 – Ephemeral, immutable – assume every component will break over the next week
The easiest way to work with Kubernetes, especially at scale and over the long term, is to ensure that ephemeral components frequently break, which may seem counterintuitive at first.
As described earlier, if your components are ephemeral by design, their failure should have no application service impact. But if you don’t proactively and regularly test failure scenarios, you will only find out your true resilience during an unplanned production incident.
Once you build confidence in your application environment’s ephemeral components, you have essentially created an immutable architecture configurable and auditable using the paradigm of infrastructure as code (IaC).
The concept of continuous integration and continuous delivery (CI/CD) uses automation to ensure that human errors don’t undermine hundreds of minor daily software releases in a Kubernetes cluster. DevOps teams operating applications on Kubernetes rely on automation, audit logs, and monitoring tools to avoid or at least quickly detect configuration mistakes in such a high-velocity operational environment.
12 – Don’t run databases on Kubernetes
Databases require high input and output (I/O) throughput, which means that they need to rapidly read and write vast amounts of data to storage volumes. Kubernetes regulates the granular sharing of CPU and memory in a cluster; however, it doesn’t do the same for storage disk access. This shortcoming means that databases can clash with other applications when reading from and writing to storage and suffer performance bottlenecks.
Furthermore, Kubernetes is ideal for hosting stateless applications that can scale horizontally via replication. Database workloads don’t fit that workload profile and are a poor candidate as a Kubernetes workload.
Dedicated virtual machines or managed database services offered by public cloud providers are the best solutions for delivering a database service. The database service would share a network with the other parts of the application hosted on Kubernetes to operate as a networked whole.
Security
Kubernetes offers many built-in security features that you should consider when designing a new deployment. This page provides a detailed list. Here we pick out some of the most fundamental security measures.
13 – Disable root access on containers
Root access to a container can lead to root access on the underlying node hosting the container when an OS process breaks out of its container. Such a breach would result in the OS process having all the privileges of the underlying host and all other containers running alongside it, thereby creating a security exposure. The best policy is to disable root access on containers and rely on Kubernetes to manage individual containers.
14 – Turn on audit logging
Enabling audit logs is a standard security measure that can also be useful in day-to-day operations. With this feature, each action by an administrator is logged in a file for future reference. Tracing configuration changes to individual administrators in a multi-user platform can help track down and correct problematic usage patterns.
15 – Use RBAC for granular control
Role-based access control (RBAC) restricts access based on the roles of individual users within an organization and should be used in a Kubernetes cluster. Kubernetes offers a flexible RBAC system that provides granular authorization levels that are sufficient for most needs and easy to maintain.
16 – Grant permissions at the pod level by default
Kubernetes allows users to control administrative access at many levels ranging from an entire cluster to individual pods. The best practice is to manage access at the pod level to avoid mistakes arising from granting access broadly across a Kubernetes cluster. Pods containing different applications generally shouldn’t share privileges.
For example, when using one of the Kubernetes service offerings by Amazon Web Services (AWS) to host a Kubernetes workload, you can attach an IAM ((Identity and Access Management) policy to an EC2 granting a user access privileges serving as a Kubernetes cluster node. However, a user controlling a cluster node can control all processes on that node, including those running inside every container. The ability of Kubernetes to automatically optimize usage by moving pods across nodes further complicates access control when granted at a node level. The mechanisms for assigning permissions to individual pods (groups of containers) are not always as convenient but reduce your application’s attack surface.
Conclusion
Kubernetes offers exceptional operational intelligence for orchestrating containers. Change procedures that used to be high-risk or required dedicated expertise are now automated and code-driven. This innovation is game-changing for increasing service quality and delivering application features faster.
However, this sophistication comes with complexity which needs thoughtful planning and new processes even when using a managed Kubernetes service offered by one of the leading public cloud providers.
The best practices presented in this article will help you avoid basic mistakes and help you realize the value that Kubernetes can bring to your application services.
You like our article?
You like our article?
Follow our monthly hybrid cloud digest on LinkedIn to receive more free educational content like this.
Consolidated IT Operations for Hybrid Cloud
Learn MoreA single platform for on-premises and multi-cloud environments
Automated event correlation powered by machine learning
Visual workflow builder for automated problem resolution